
下面部分是从Wikipedia提取的信息,英文是原文,中文是我对这个的理解。
Event-driven Architecture
event a significant change in state
Event structure
An event can be made of two parts,header and body.The event header might include information such as event name, timestamp for the event, and type of event. The event body is the part that describes the fact that has happened in reality.
事件内部的数据组织结构,包括一些描述事情本身的信息(如名称,时间,类型,状态等)和需要进行业务处理的数据。
事件驱动构架的分层结构
Event flow layers
1.Event generator
用来生成 Event,生成一个包括当前fact的Event.需要将许多不同的应用程序产生的数据转换成标准化的数据是这一层设计和实现的一个难题。
2.Event channel
An event channel is a mechanism whereby the information from an event generator is transferred to the event engine or sink.
事件传播的一个渠道,实现方式可以有许多种。
Event processing engine 事件处理引擎
The event processing engine is where the event is identified, and the appropriate reaction is selected and executed.
事件处理引擎,接收事件,按照事件的类型来选择不同的处理策略,并处理事件。
downstream event-driven activity
This is where the consequences of the event are shown.
Event processing styles
Simple event processing
Simple event processing concerns events that are directly related to specific, measurable changes of condition.
这种方式是接收到事件后,根据事件的类型直接进行处理,也就是事件分类与处理放在一起处理。
the application has a main loop which is clearly divided down to two sections: the first is event selection (or event detection), and the second is event handling
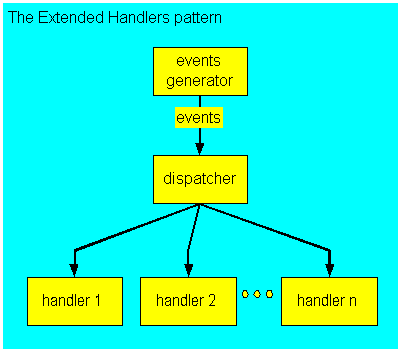
这种方式把事件的分类与真正的业务处理分开。 事件分类可以看成是一个事件的分发器,将事件分发到相应的处理器上进行处理。 这种方式会有更好的效率,而且更易扩展。
下面图片来自http://eventdrivenpgm.sourceforge.net/
下面另外一个系列文章中整理出来的一些key points.
Architectures are composed of the following:
1. Components: The elements that form a system. For example, the components of a bridge are beams, cables, and trusses.
2. Compositional operators: The mechanisms for plugging components together to get other components. For example, smaller trusses can be welded together to form larger trusses.
3. Contracts: The specifications for what users of components can expect from them.
EDA has two components: streams and agents (also called processes). A stream is a sequence of messages that have a common schema. Streams are either event streams or control streams. Messages in event streams contain information about the system state.
There are three types of agents:
* Sensors a sensor is a source of data。
* Responders
* Processing agents (or EPAs for event processing agents)
Sensors monitor the environment and generate event messages that contain information about the attributes that they monitor.
A responder receives an event stream and modifies the state of the environment based on the stream.
One can think of responders in two ways: either as a software module that receives an event stream and controls a device based on the events it receives, or as the device itself.
Event-processing agents receive multiple streams of messages, process them, and generate message streams in turn
In animals, sensors are eyes and other sensory organs, the nervous system is a network of EPAs, and muscles are responders.
A key point in such an event-driven system is the absence of messages conveys information.


references:
http://www.developer.com/design/article.php/3490671
http://www.developer.com/design/article.php/10925_3499031_1
http://elementallinks.typepad.com/bmichelson/2006/02/eventdriven_arc.html